Organizing Unstructured Data
Managing data complexity using types, structures, ADTs, and objects
Topics
The main, if not the only, purpose of a computer is to compute information. It doesn't always have to be a computation of mathematical formulas. In general, it is a transformation of one piece of information into another. Computers only work with information that can be represented as discrete data. The input and output of a computer engine are always natural numbers or text (a sequence of symbols from a dictionary that correspond to certain natural numbers).

As long as data is unstructured, it's hard to make some sense of it. But once data is given a structured form, it becomes meaningful and suitable for further transformation.
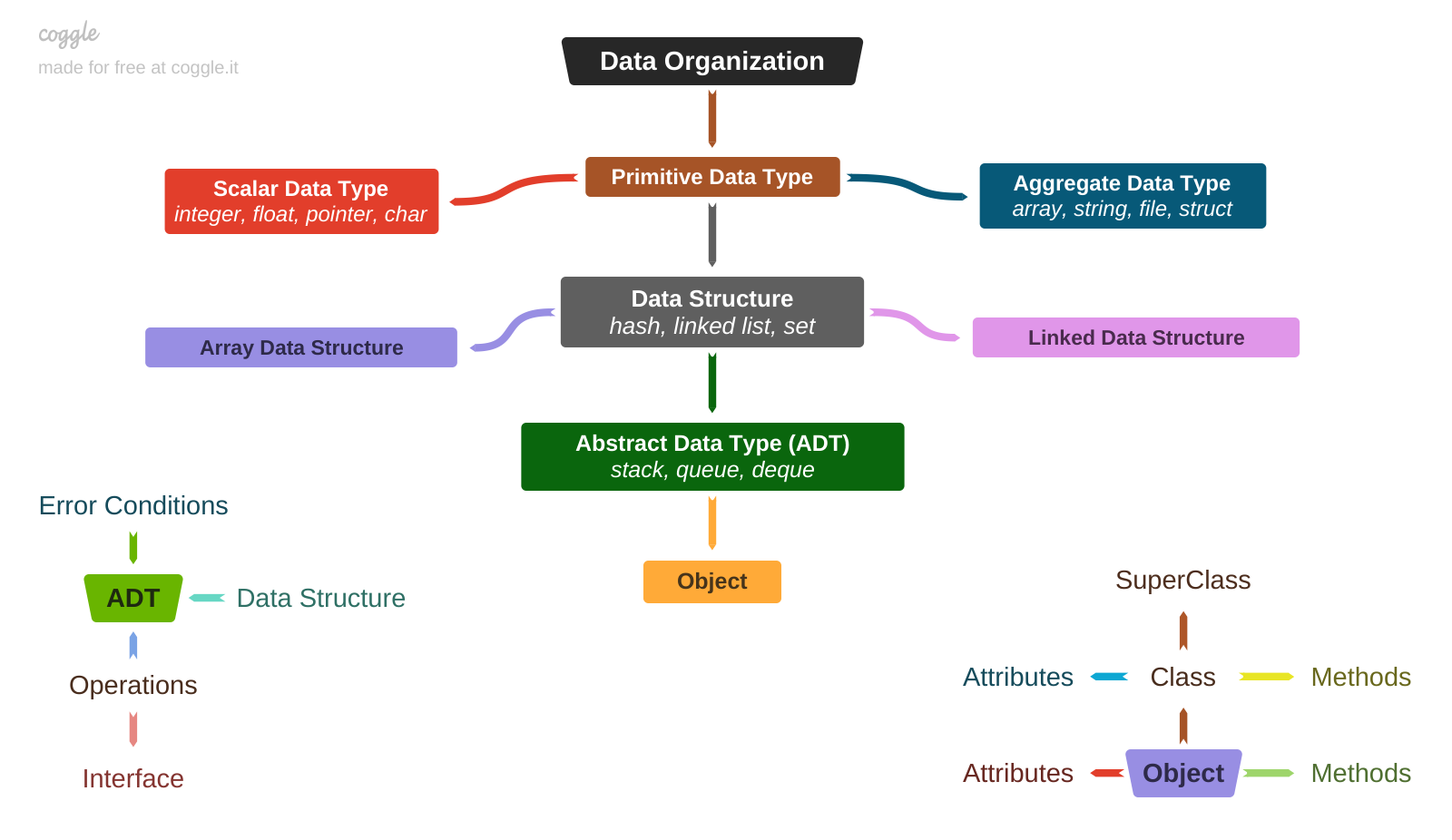
Type
The simplest form of data organization is Type. In general, a data type defines a set of values with certain properties. It usually defines a size in bytes. A primitive data type is an ordered set of bytes. When a variable of a primitive data type has only one value (holds only one piece of information), it's called a scalar and a type - scalar data type. Well-known examples are integer, float, pointer, and char. A collection of primitive (scalar) data types is called an aggregate data type, and it allows multiple values to be stored. This can be a homogeneous collection, where all elements are of the same type, such as an array, a string, or a file. Or it can be heterogeneous, where elements are of different types, such as a structure or a class. The main property is an ordered set of bytes. The internal organization is simple, straightforward, and all actions (e.g. reading or modifying) are performed directly on the data, according to a hardware architecture that defines the byte order in memory (little-/big-endian).
Data Structure
The next level of data abstraction is called Data Structure. It brings more complexity, but also more flexibility to make the right choice between access speed, ability to grow, modification speed, etc. Internally, it's represented by a collection of the scalar or aggregate data types. The main focus is on the details of the internal organization and a set of rules to control that organization. There are two types of data structures that result from a difference in the memory allocation of the underlying elements:
- Array Data Structures (static), based on physically contiguous elements in memory, with no gaps between them;
- Linked Data Structures (dynamic), based on elements, dynamically allocated in memory and linked in a linear structure using pointers (usually, one or two)
Well-known examples are linked list, hash (dictionary), set, list. These data structures are defined only by their physical organization in memory and a set of rules for data modifications that are performed directly. All internal implementation details are open. The actions performed on the data structures (add, remove, update, etc.) and the ways in which they are used can vary.
Abstract Data Type (ADT)
A higher level of data abstraction is represented by an Abstract Data Type (ADT), which shifts the focus from "how to store data" to "how to work with data". An ADT represents a logical organization, defined mainly by a list of predefined operations (functions) for manipulating data and controlling its consistency. Internally, data can be stored in any data structure or combination thereof. However, these internals are hidden and should not be directly accessible. All interactions with data are done through an interface (operations exposed to users). Most of ADTs share a common set of primitive operations, such as
- create - a constructor of a new instance
- destroy - a destructor of an existing instance
- add, get - the set-get functions for adding and removing elements of an instance
- is_empty, size - useful functions for managing existing data in an instance
The most common examples of ADTs are stack and queue. Both of these ADTs can be implemented using either array or linked data structures, and both have specific rules for adding and removing elements. All of these specifics are abstracted as functions, which in turn, perform appropriate actions on internal data. Dividing an ADT into operations and data structures creates an abstraction barrier that allows you to maintain a solid interface with the flexibility to change internals without side effects on the code using that ADT.
Object
A more comprehensive way of abstracting data is represented by Objects. An object can be thought of as a container for a piece of data that has certain properties. Similar to the ADT, this data is not directly accessible (known as encapsulation or isolation), but instead each object has a set of tightly bound methods that can be applied to operate on its data to produce an expected behavior for that object (known as polymorphism). All such methods are really just functions collected under a class. However, they become methods when called to operate on a particular object. Methods can also be inherited from another class, which is called a superclass. Unlike an ADT, an object doesn't represent a particular type of data, but rather a set of attributes, and it behaves as it should when its methods are invoked. Attributes are nothing more than variables of any type (including ADTs). Formally speaking, classes act as specifications of all of the object's attributes and the methods that can be invoked to deal with those attributes.
The Object-Oriented Programming (OOP) paradigm uses objects as the central elements of a program design. At program runtime, each object exists as an instance of a class. The class, in turn, plays a dual role: it defines the behavior (through a set of methods) of all objects instantiated from it, and it declares a prototype of data that will carry some state within the object once it's instantiated. As long as the state is isolated (incapsulated) in the objects, access to that state is organized by communication between the objects via message passing. It's usually implemented by calling a method of an object, which is equivalent to "passing" a message to that object.
This behavior is completely different from the Structured Programming Paradigm, which instead of maintaining a collection of interacting objects with an an embedded state, relies on dividing of a project's code into a sequence of mostly independent tasks (functions) that operate with an externally (to them) stored state.